NeurIPS 2024 · December 2024
InterpBench: Semi-Synthetic Transformers for Evaluating Mechanistic Interpretability Techniques
Tl;dr: We provided a new way to train models to follow predefined Tracr circuits, and then made a benchmark out of those models to evaluate circuit discovery methods.
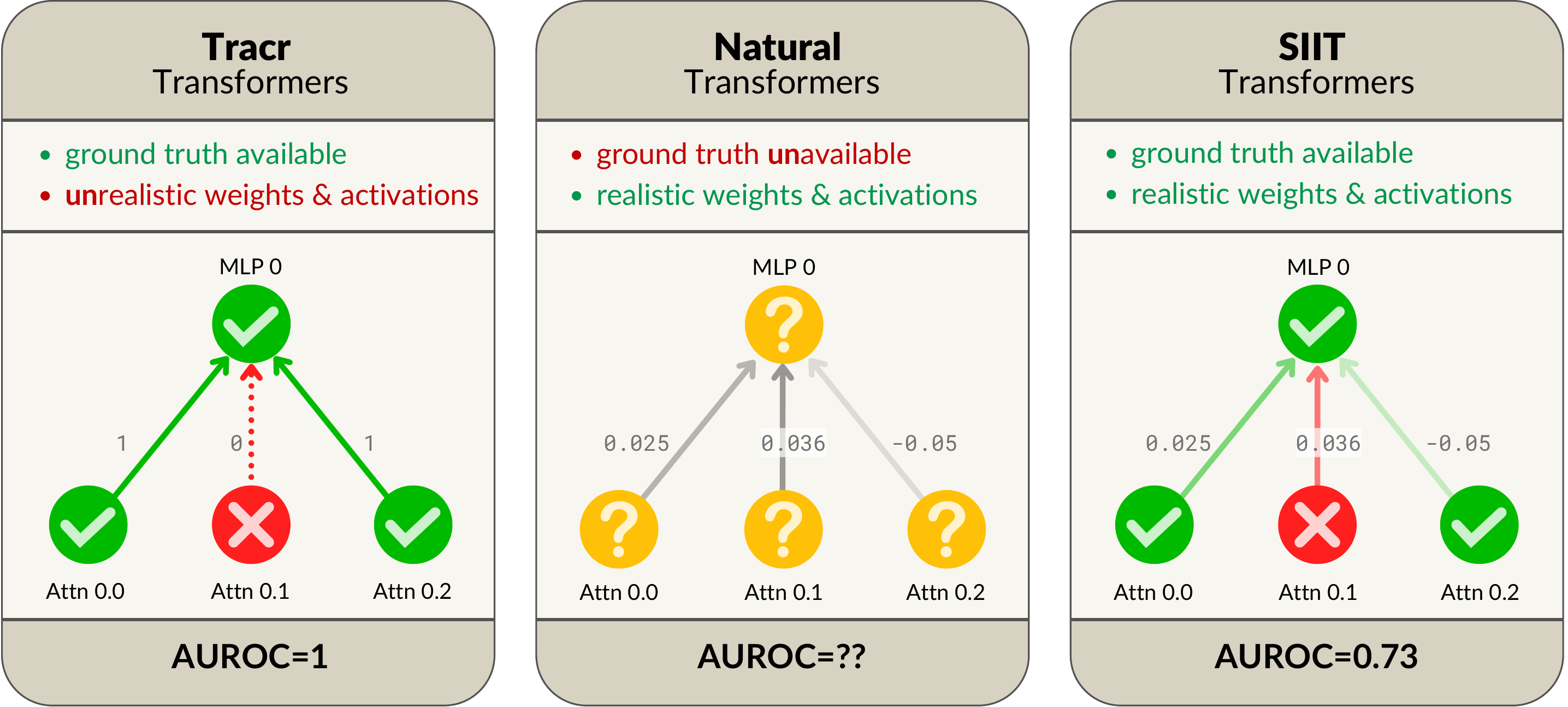
The problem
This work follows Interchange Intervention Training (IIT). They claimed that they could train circuits into a model using this method, which resample ablates nodes and uses a behavioral loss that says: “If this node behaves the way I want to, it should induce this change to the final answer”. If resample ablation doesn’t do that, penalise the model.
However, there is a problem with this:
There are many nodes in the transformer that won’t be a part of the circuit. They should ideally do nothing, but the loss doesn’t penalise for that. As a result, we can get a counter example like above. If this was too confusing, here is a set of slides that show this in a Tracr circuit:








Geiger et al. actually had a proof showing their models ‘faithfully follow a high-level abstraction’ which said that if loss is 0 on this task, the ‘high-level structure’ we defined is a constructive abstraction in the sense of Beckers & Halpern. However, their definition of the set of possible interventions ignored these nodes we saw altogether. So their proof makes sense under this definition, but it isn’t what we want. I made Claude formally write this down for whoever that might need this (I highly doubt anyone will):
Show the formal counterexampleHide the formal counterexample
Geiger et al. claim that loss = 0 makes the high-level model a constructive abstraction of the network in the sense of Beckers & Halpern. But constructive abstraction (B&H Def 3.19) requires strong abstraction, which quantifies over all τ-compatible interventions on the low-level model — including the out-of-circuit nodes their loss never touches. So the relation they actually verify is a strictly weaker thing.
Claim. There exists a network and alignment such that the IIT loss is exactly zero, yet is not a constructive -abstraction of in the sense of Beckers & Halpern. Concretely: a single intervention on an out-of-circuit hidden unit flips the network’s output while leaving the high-level model’s output unchanged — a violation that IIT’s loss is structurally incapable of detecting because it never intervenes there.
What Geiger et al. claim. They define the IIT abstraction condition (Eqn. 2) as
and write, immediately after, that “this is in fact a constructive abstraction relationship in the sense of Beckers & Halpern (2019)”. is summed only over and aligned variables , with interventions confined to the aligned neurons .
What B&H actually require. A constructive -abstraction (B&H Def 3.19) is by definition a strong -abstraction (Def 3.15) whose factors through a partition of . Strong -abstraction demands that be a -abstraction of where is the full set of low-level interventions on which is defined — not just interventions on the aligned .
Where the gap lives. Take any out-of-circuit cluster and any assignment . Because varying the aligned variables already covers every high-level state, , so applying B&H Def 3.12 gives
These interventions therefore lie in , and constructive abstraction requires
IIT’s loss never evaluates a single such intervention.
A concrete counterexample. Let with input , structural equation , and output . Let have two hidden units satisfying and , with output logit
Align and take the partition , with .
- IIT loss is zero. For any , intervening only on gives , so . ✓
- Not a strong -abstraction. Take with : , so . But . ✗
So does not imply that is a constructive -abstraction of in the Beckers–Halpern sense. What it implies is the weaker statement actually proved: aligned interchange interventions agree. SIIT plugs the hole by adding a loss term over interventions — exactly the condition missing above.
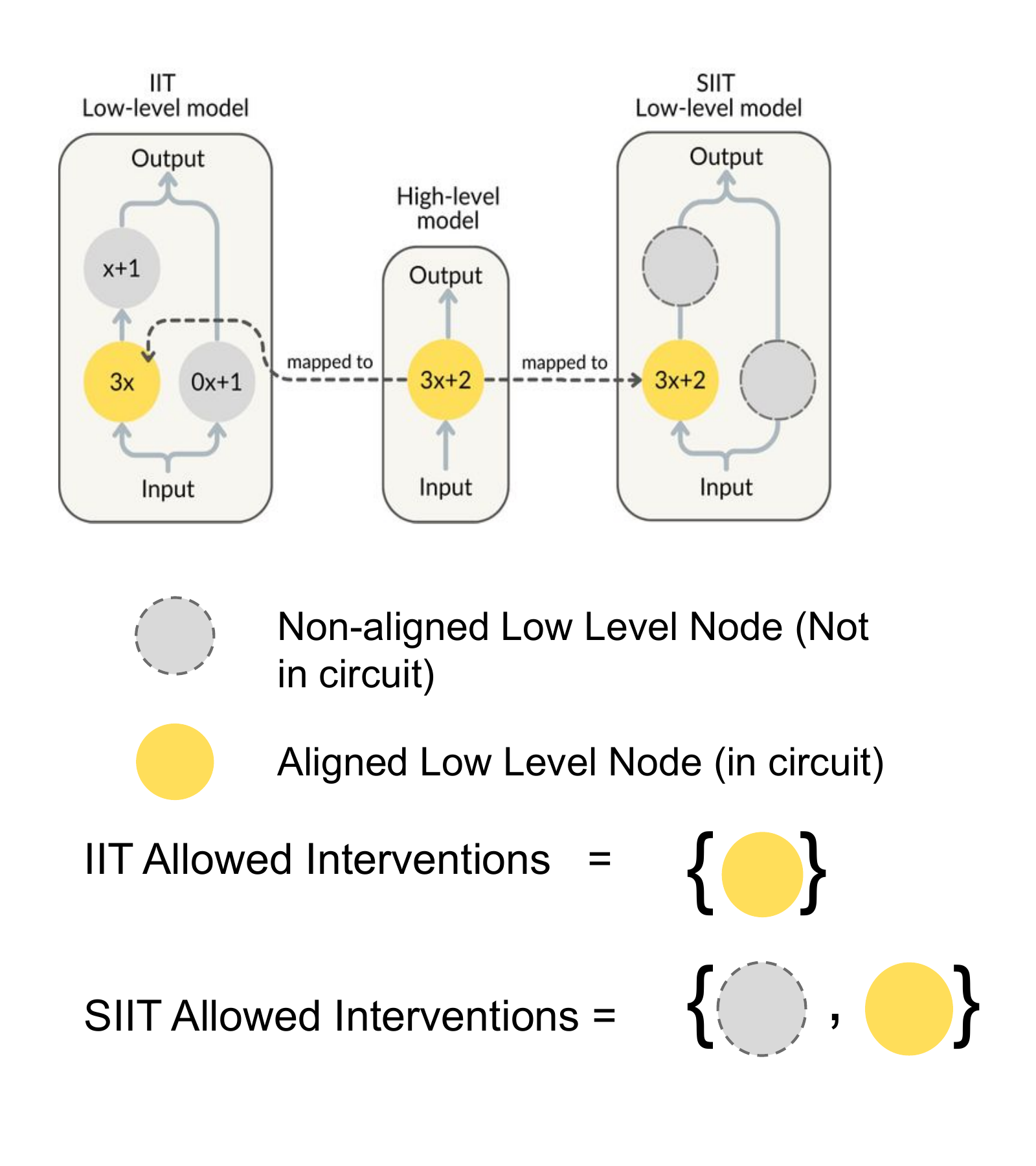
The fix
How to fix this? Just force those nodes to do nothing:
- resample ablate at a node that shouldn’t be a part of the circuit
- the output should be exactly the same
There are other methods we considered (like stopping gradients flow outside our circuit, or freezing weights not in the circuit), but none worked as well as the simplest fix — maybe because we used really small residual stream sizes and started with raw initialized model (the non-circuit nodes would always add noise to the dimension where the signal was supposed to be, and the fix I described above drastically decreased some of these nodes’ magnitudes).
But we fixed it:
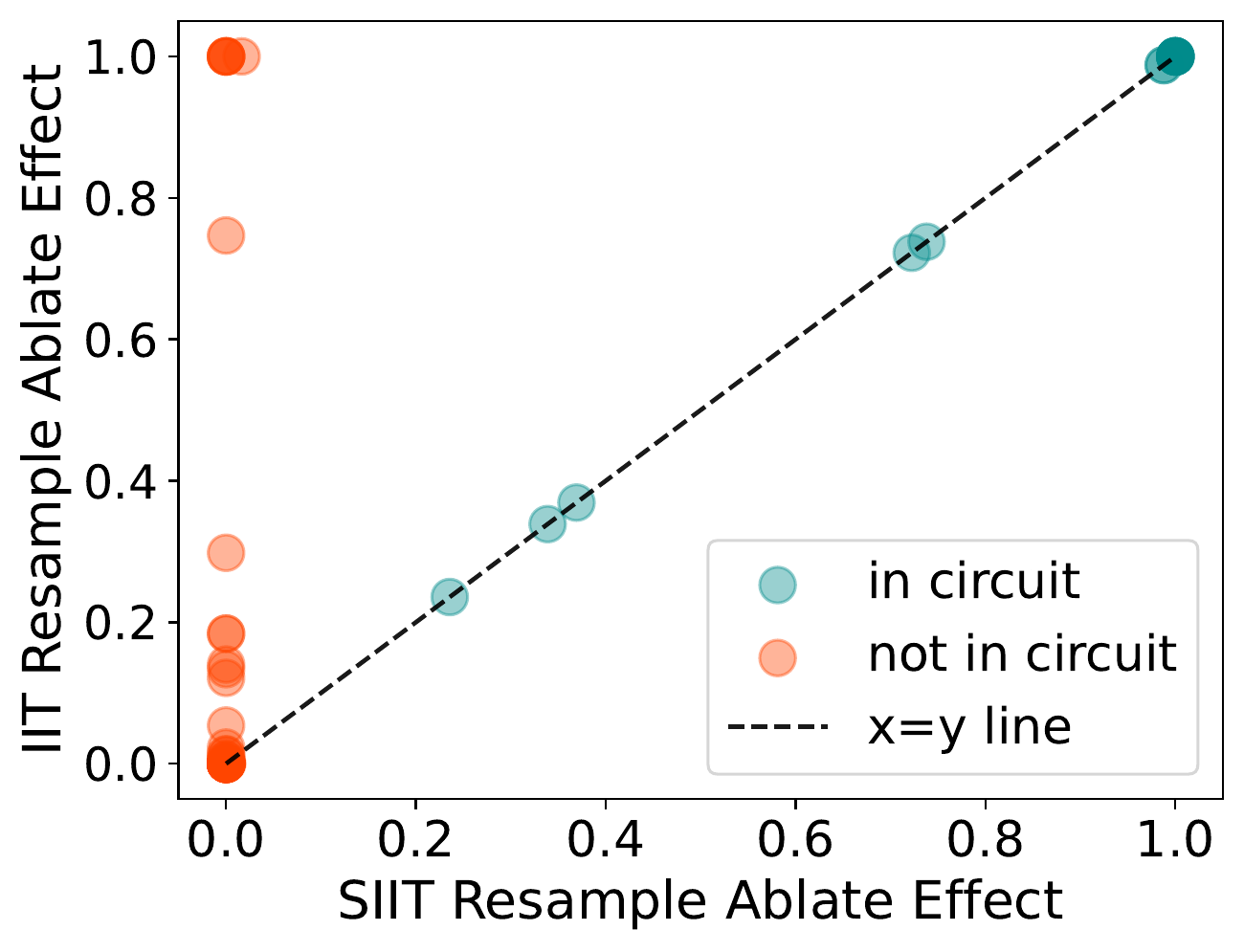
Hey, we even trained an IOI model.

This also successfully made me evaluate the models we trained like a paranoid person. I’ll leave those experiments to be read with the paper, if you’re interested.
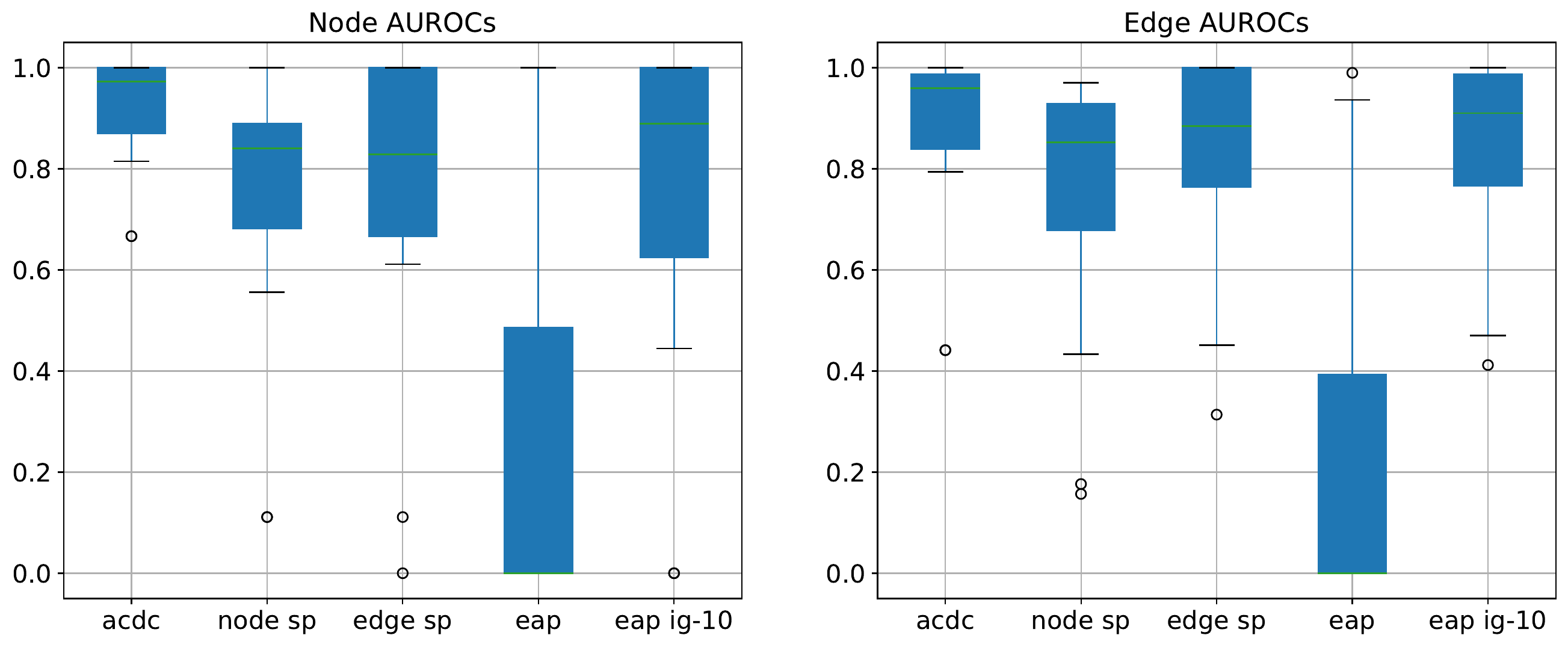
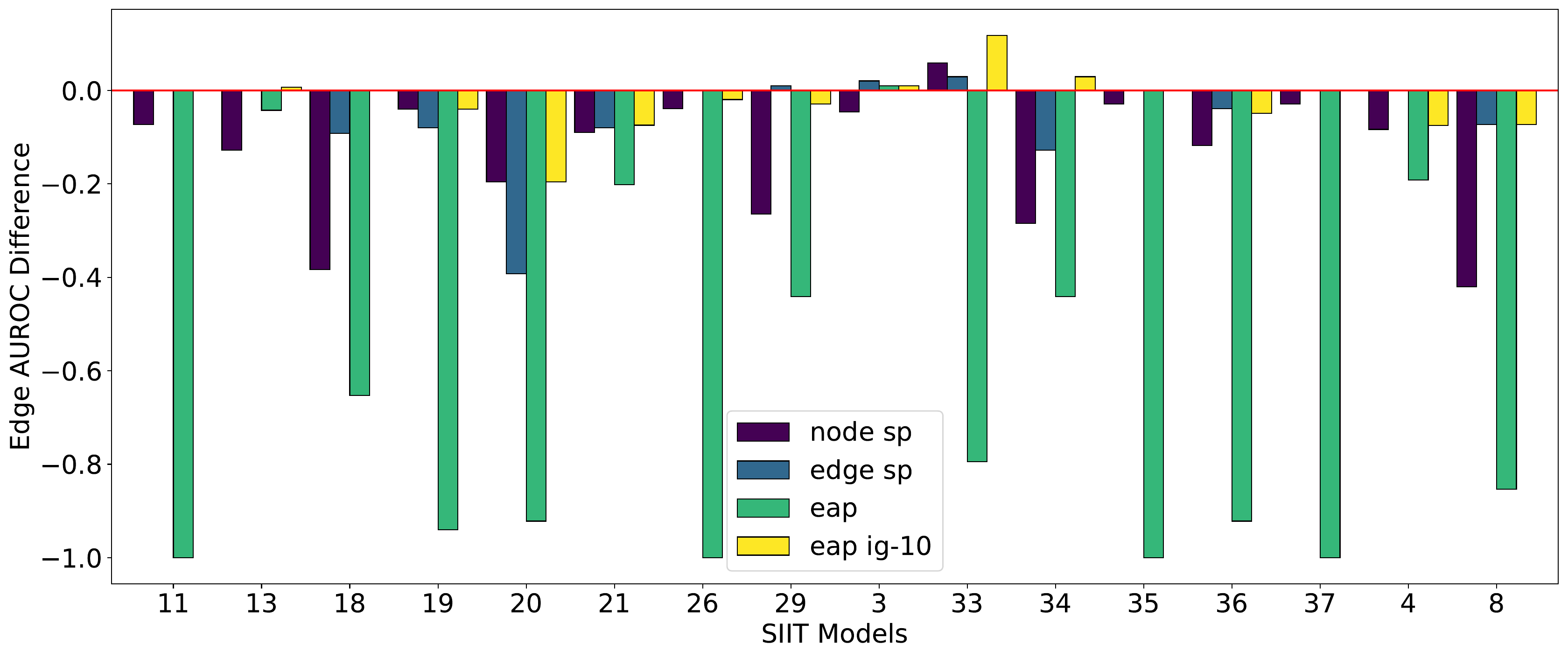
The Benchmark
- ACDC works best,
- Subnetwork Probing is the most expensive but was underwhelming,
- EAP really benefits from integrated gradients
The Impact
Was this useful? Not really. Things don’t scale. It took us way too long to get it working on Tracr. We need to artificially add things like inter-node superposition, and the number of interventions blows up exponentially if done naively (similar sentiment to what was explained above- we need to make sure everything does exactly what we want). Activation-based circuit discovery is doomed. We now have reasoning models and mega agent clusters.
This was super elegant and interesting at the time, alas, it was completely useless. I should really just move to behavioral safety research (I still haven’t lmao).